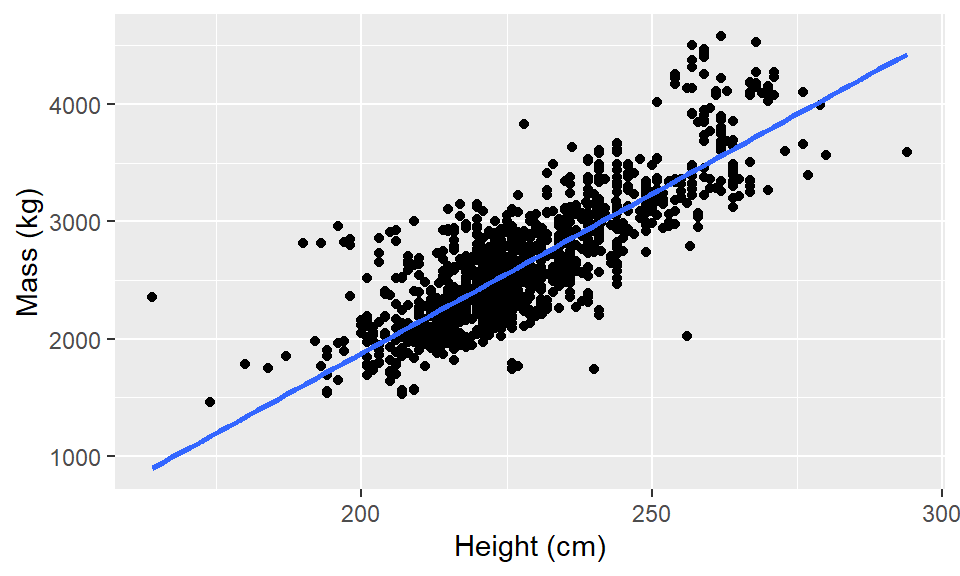
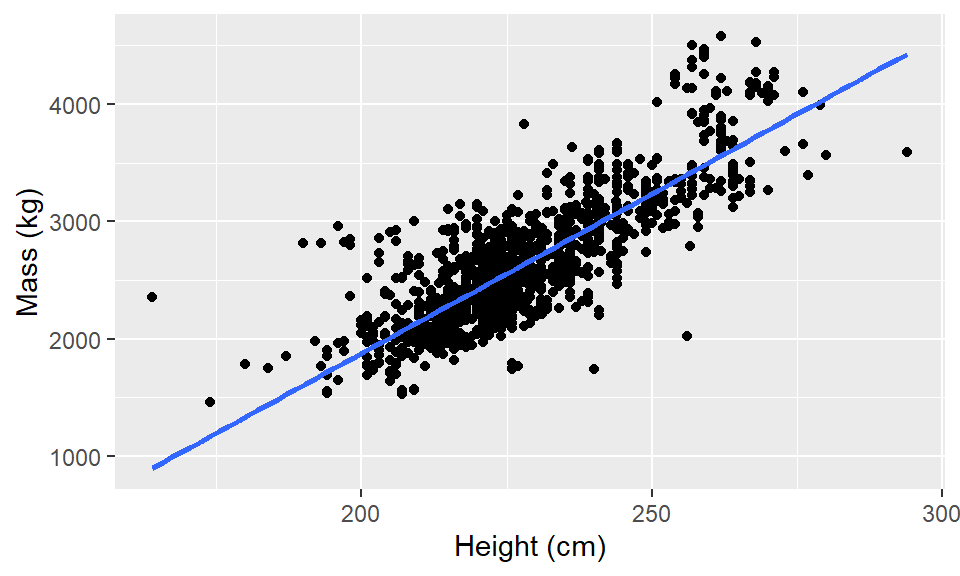
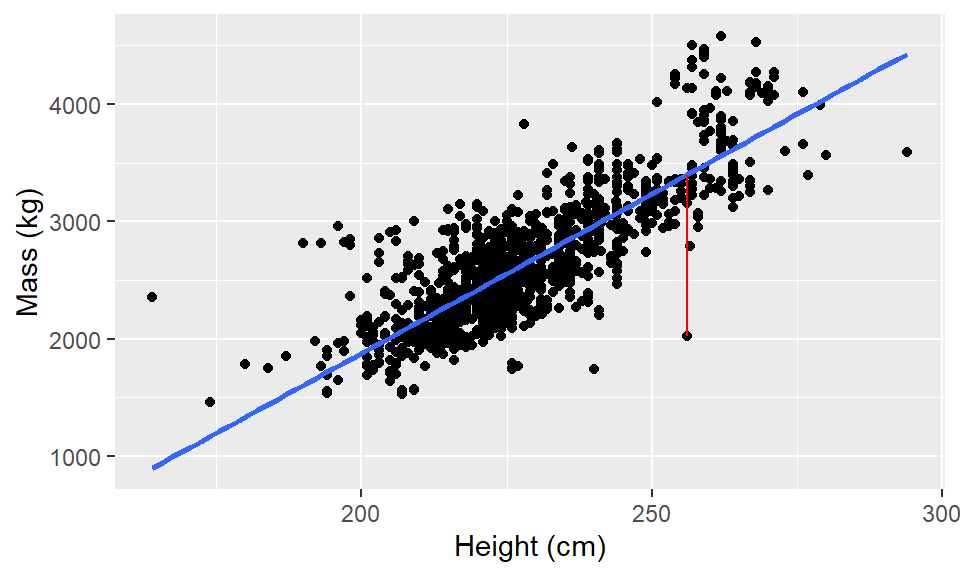
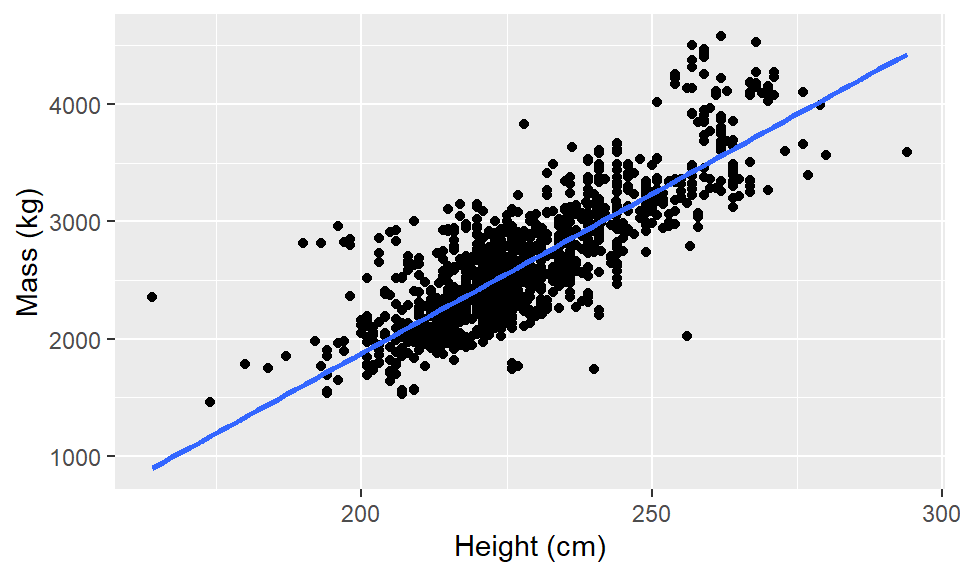
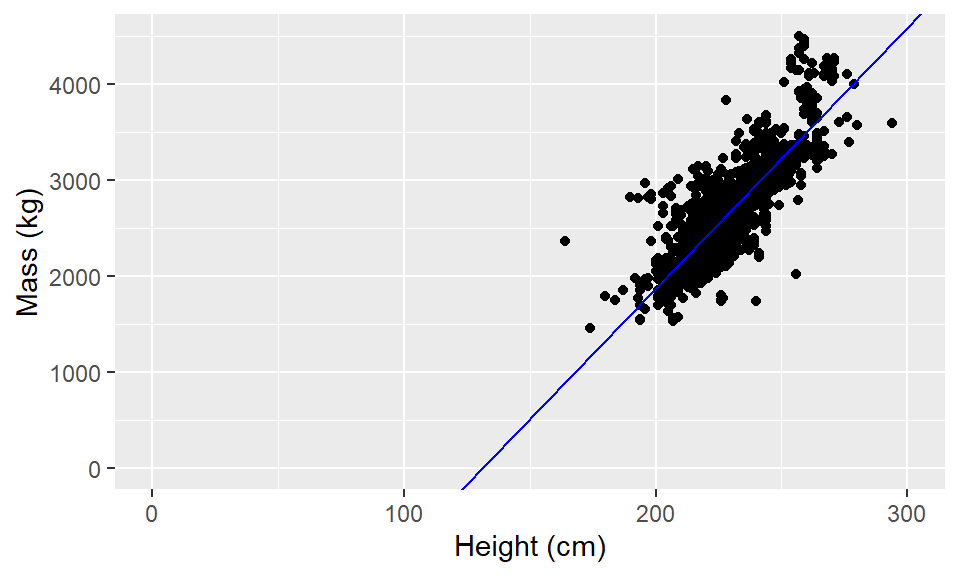
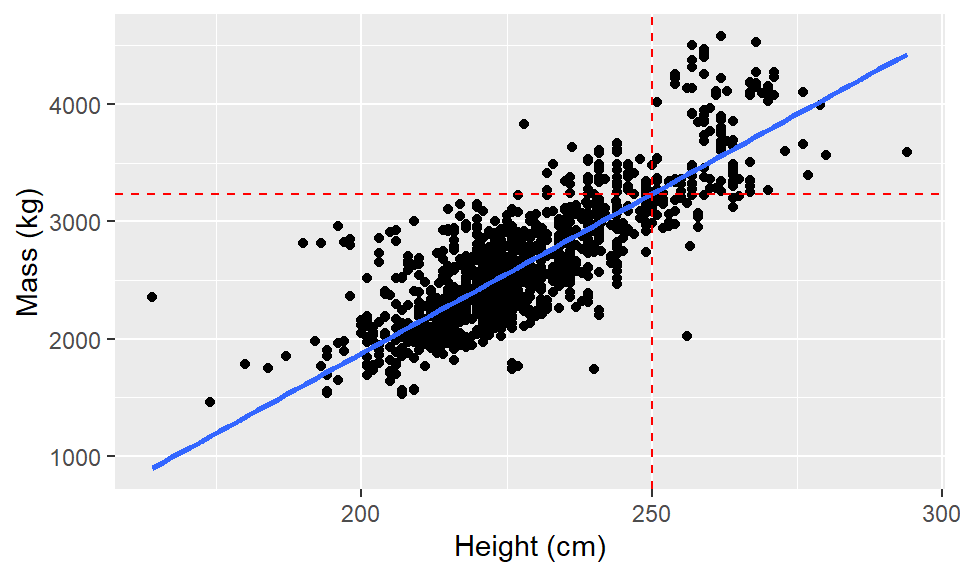
elephants <- read_csv(
"http://csuci-math430.github.io/lectures/data/elephants.csv",
show_col_types = FALSE
)
glimpse(elephants)Rows: 1,470
Columns: 5
$ Sex <chr> "B", "B", "B", "B", "B", "B", "B", "B", "B", "B", "B", "B", "B"…
$ Age <dbl> 58.96235, 59.03901, 59.12389, 59.29090, 59.37303, 59.45791, 59.…
$ Chest <dbl> 359, 359, 359, 361, 360, 359, 361, 357, 360, 364, 355, 355, 325…
$ Height <dbl> 252, 252, 252, 253, 255, 254, 255, 256, 254, 255, 251, 257, 258…
$ Mass <dbl> 3244, 3182, 3239, 3336, 3317, 3357, 3358, 3155, 3334, 3357, 324…