Math 430: Lecture 5a
Linear Regression Conditions
Recall our linear regression from last week
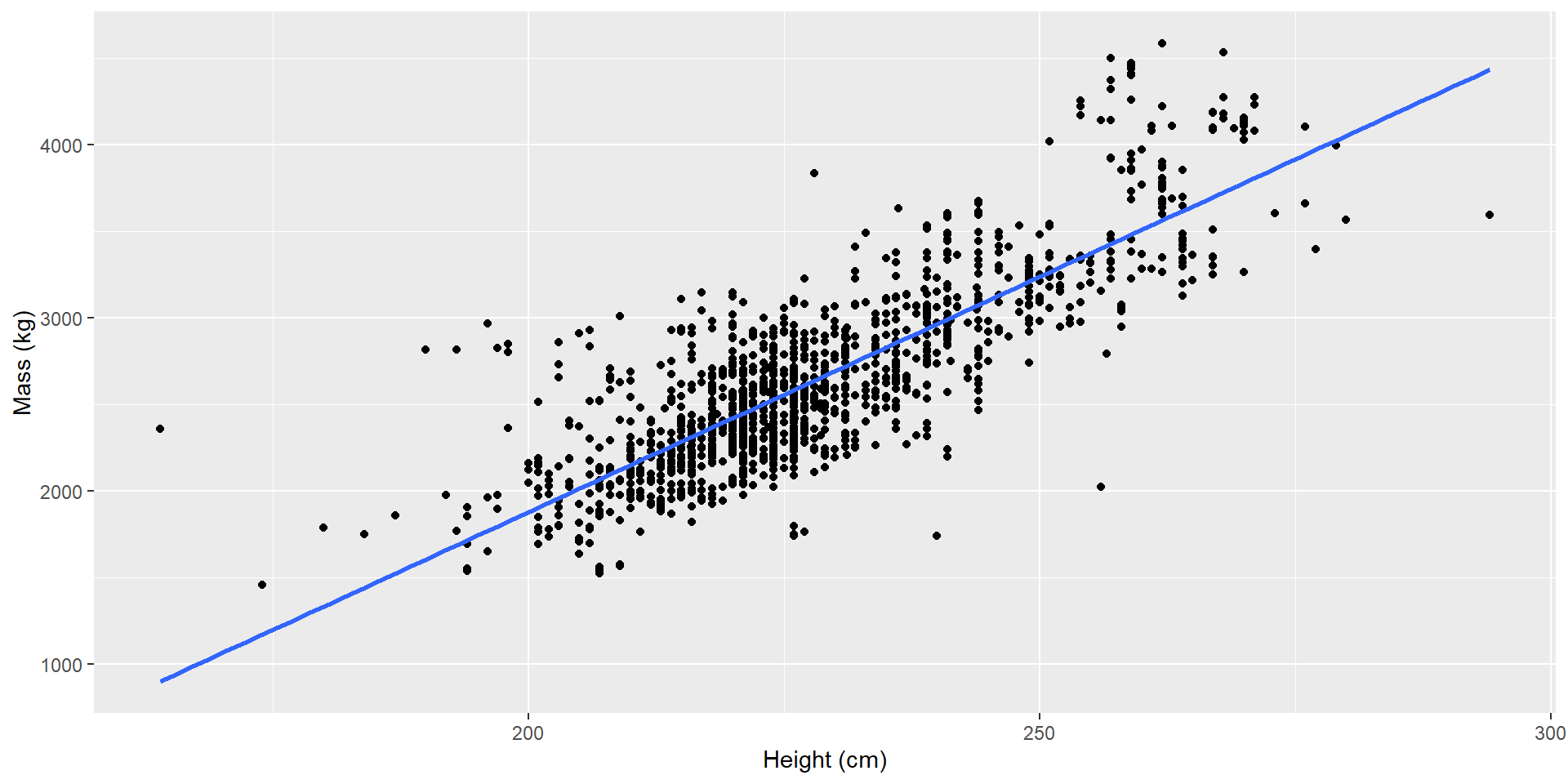
Was this model appropriate?
Why would we care if the model is “appropriate”?
- it may be chance that we got a good fit for our sample, but the model might be a bad fit for the population
- our estimates relied on our conditions, so if those don’t hold our estimates are meaningless
Visual checks
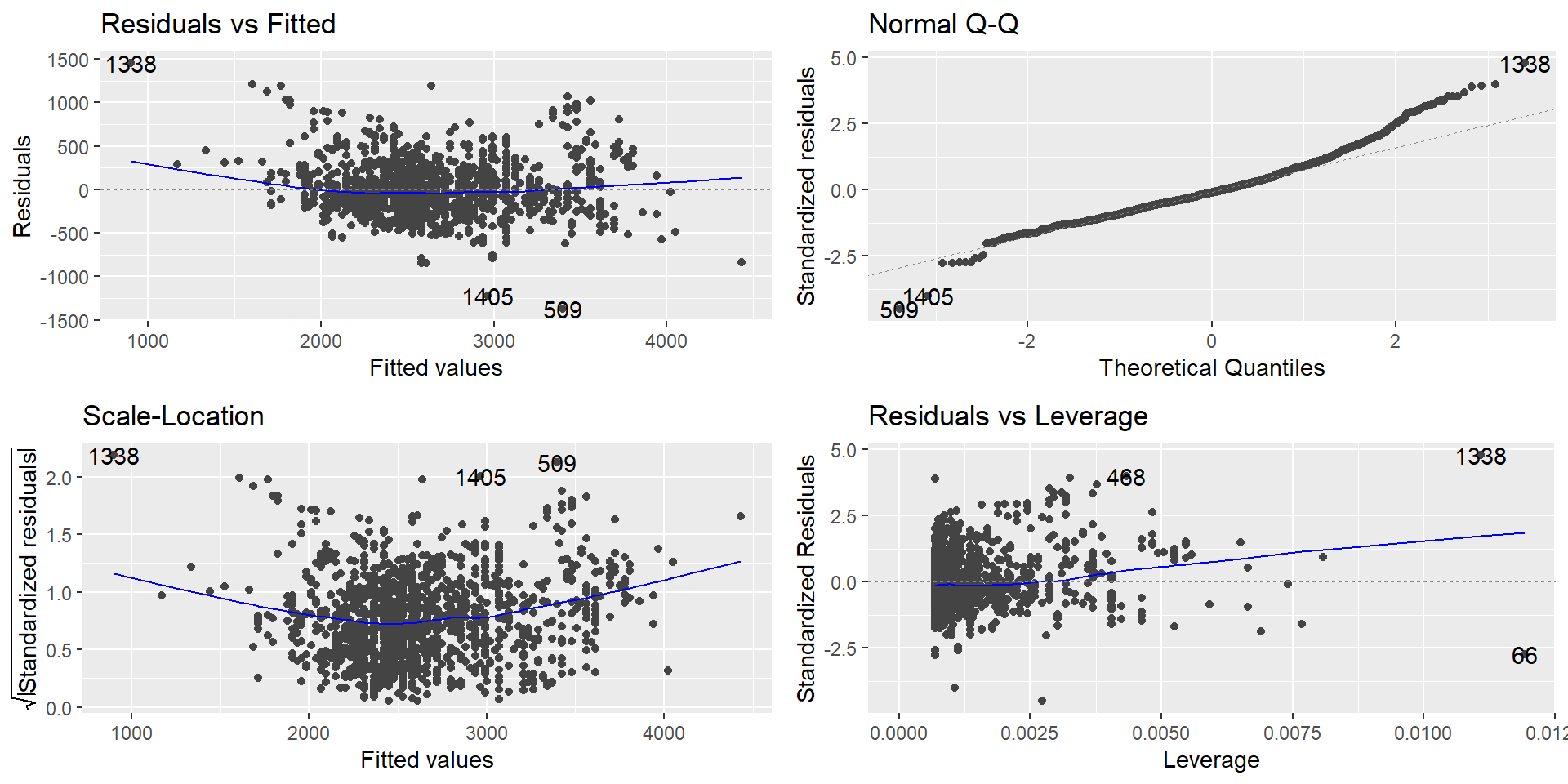
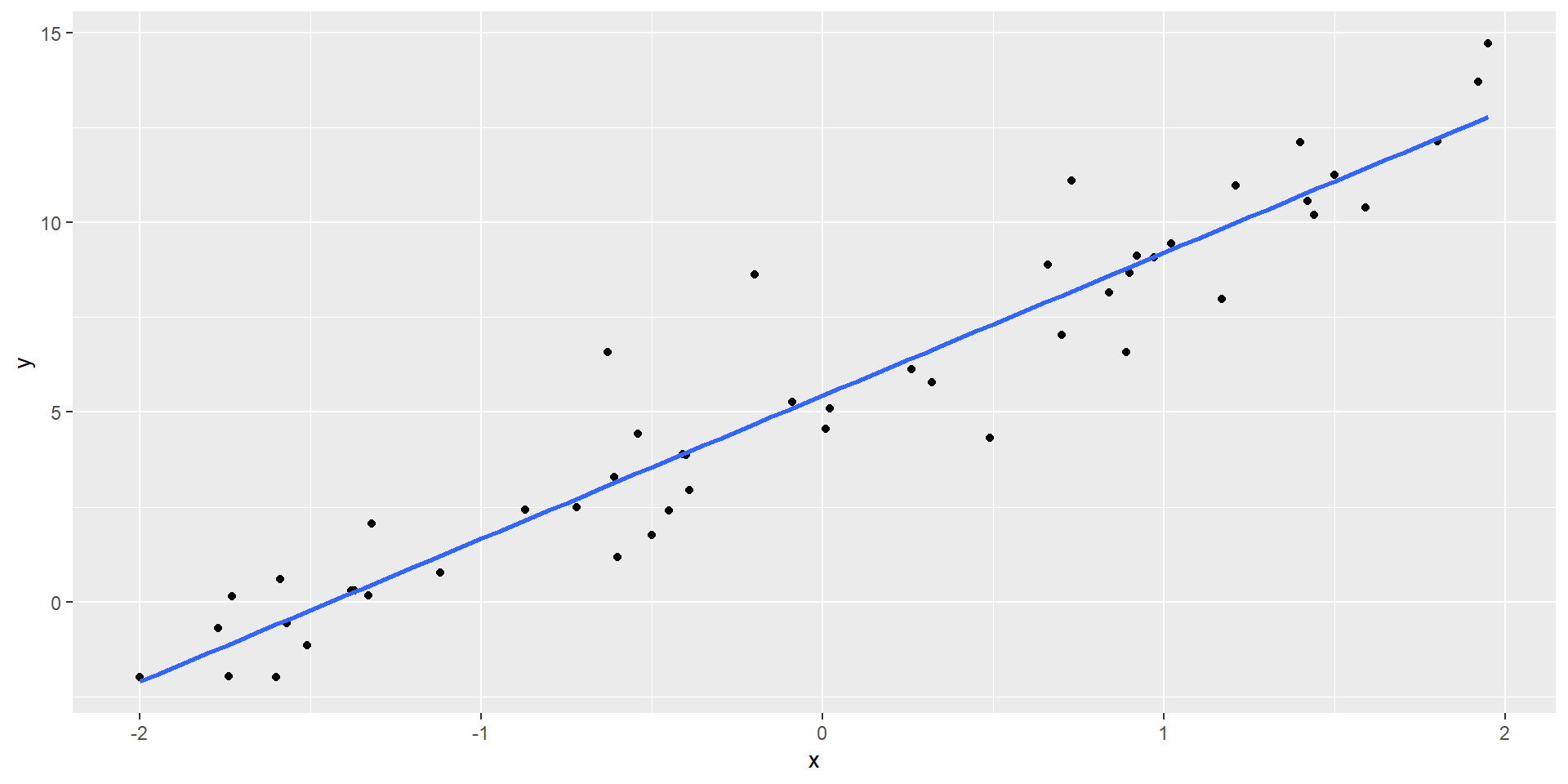
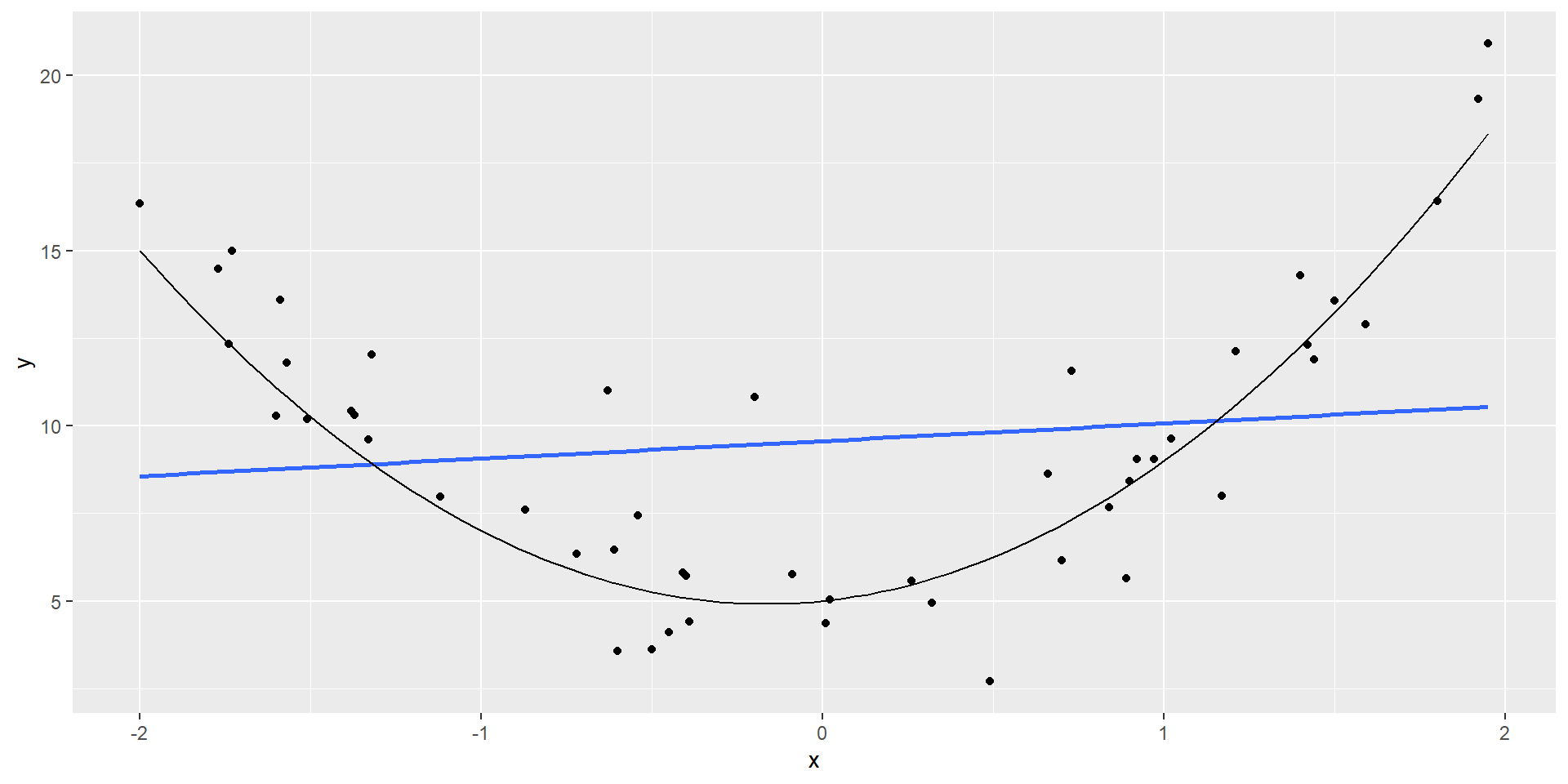
Diagnosing linearity
- Examine plot of residuals vs fitted (or predictor for simple linear regression)
- There should be no discernible pattern the the residuals centered around 0
Linear
Non-linear
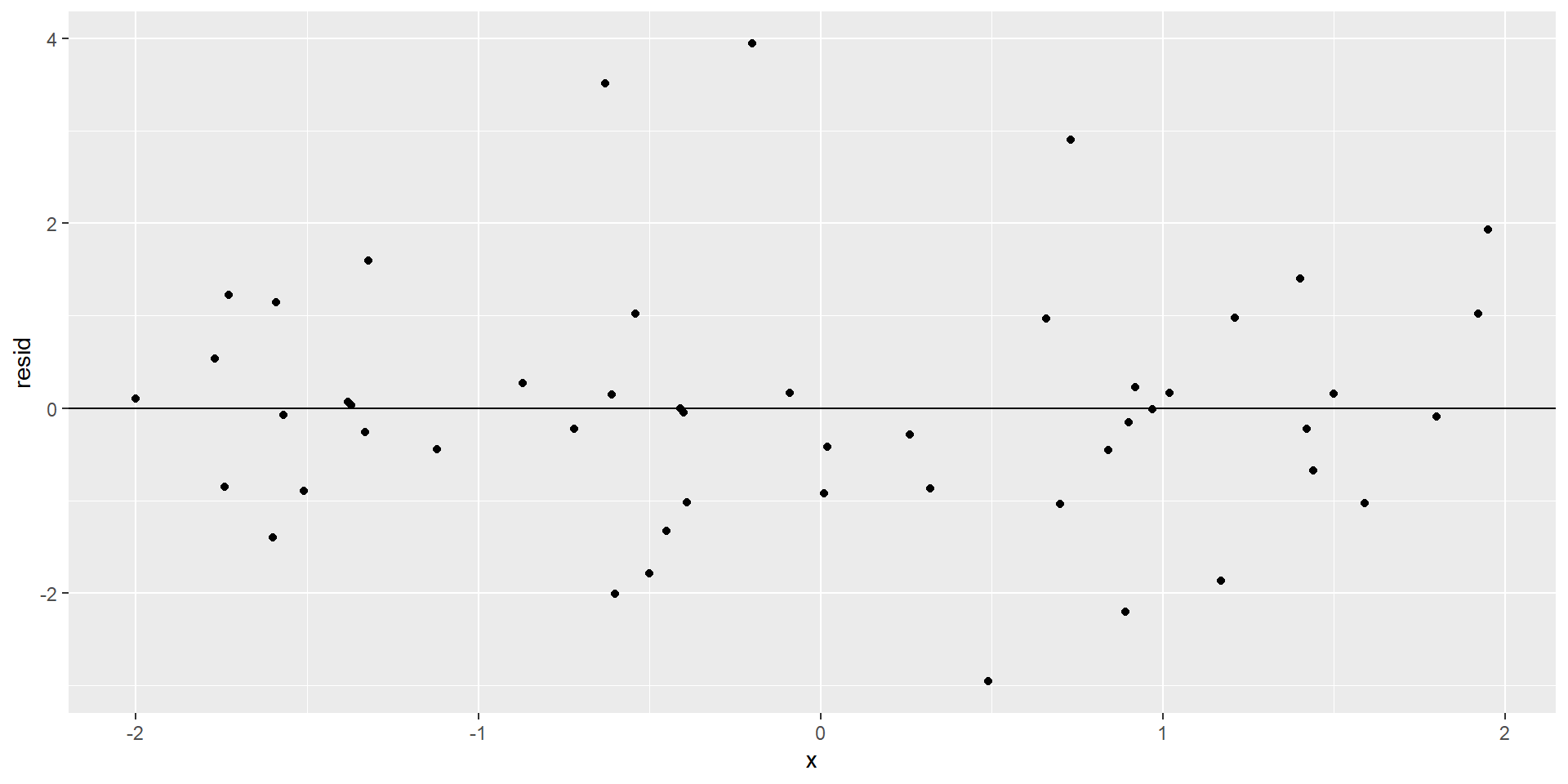
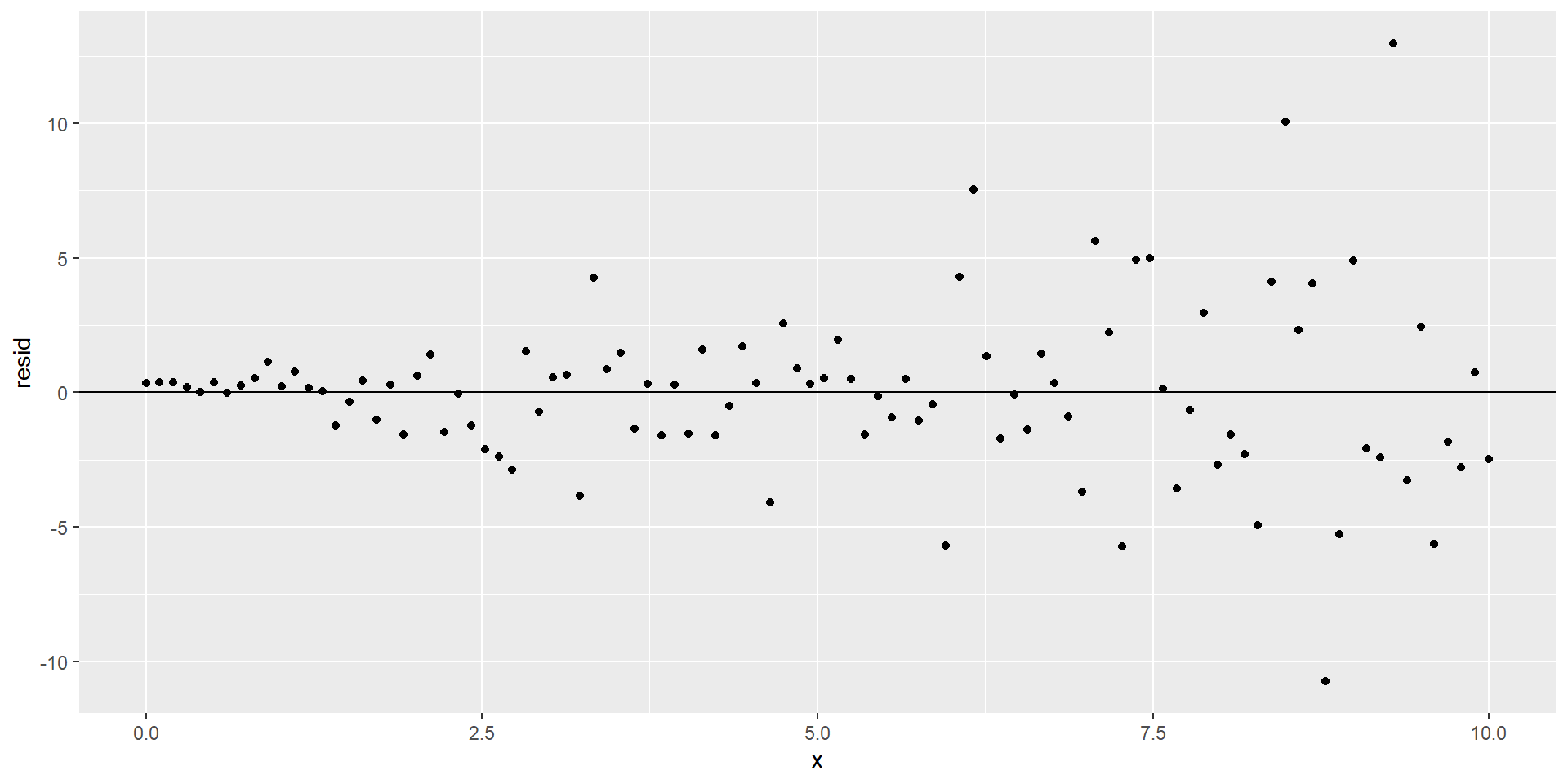
Diagnosing homoskedasticity
- Examine plot of residuals vs fitted and check there is not a “funnel-shape”
- Specifically, for each fitted value does the spread of the residuals look similar?
Constant variance
Non-constant variance
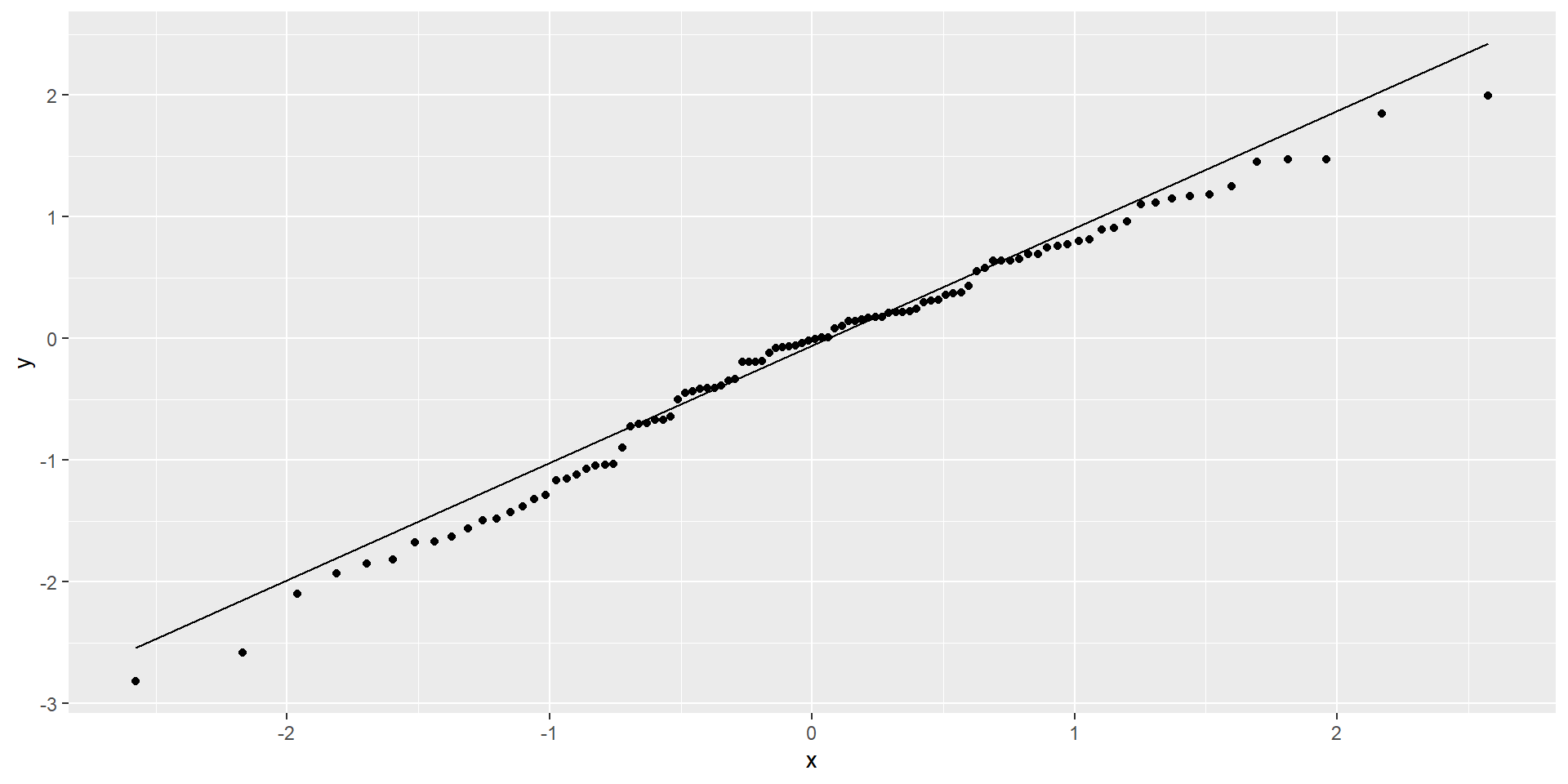
Diagnosing normality
- Assess visually with Q-Q plot
- Outliers (point with extreme residual) can result in violation of normality
Non-normal residuals
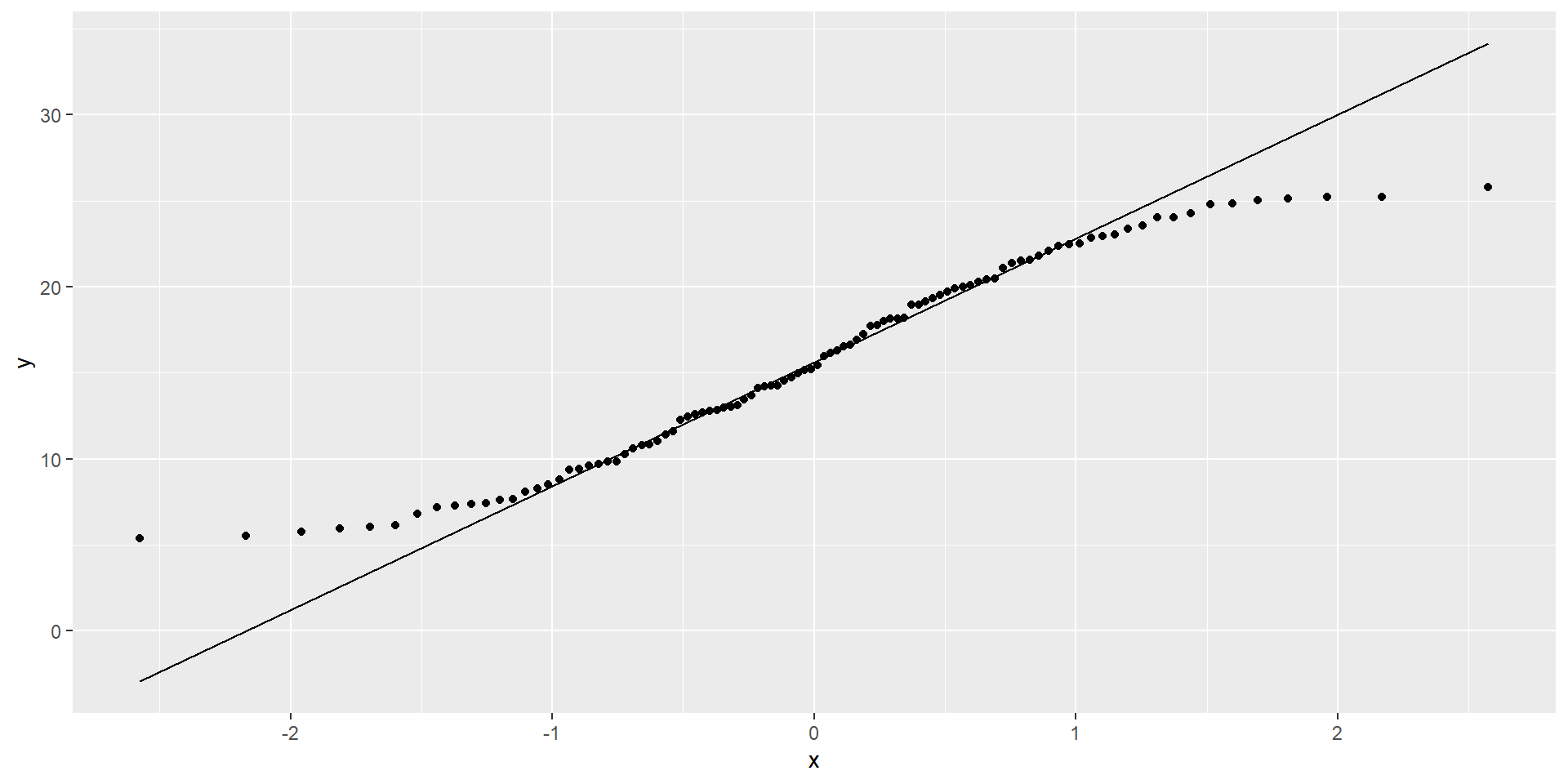
Normal residuals