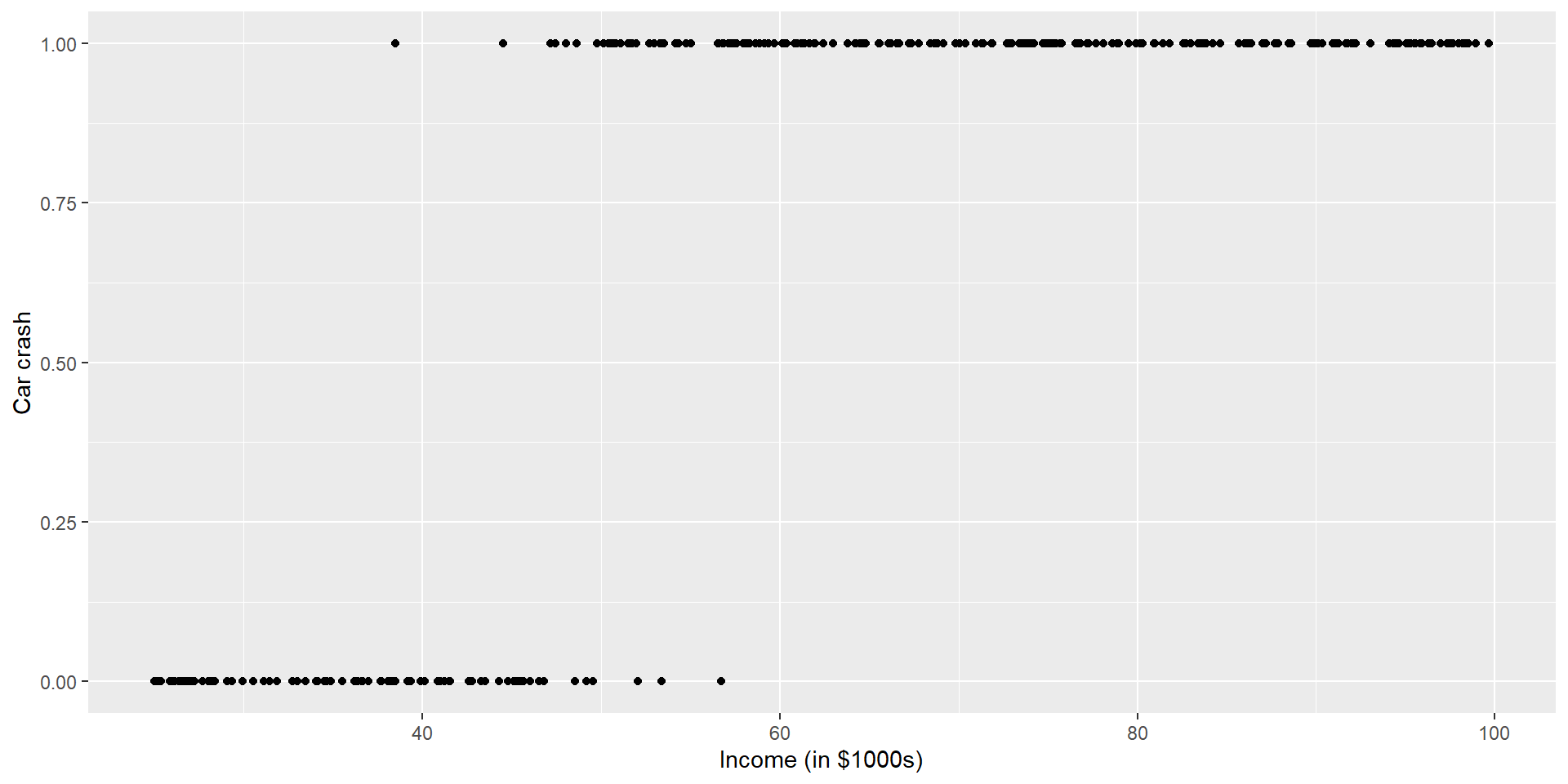
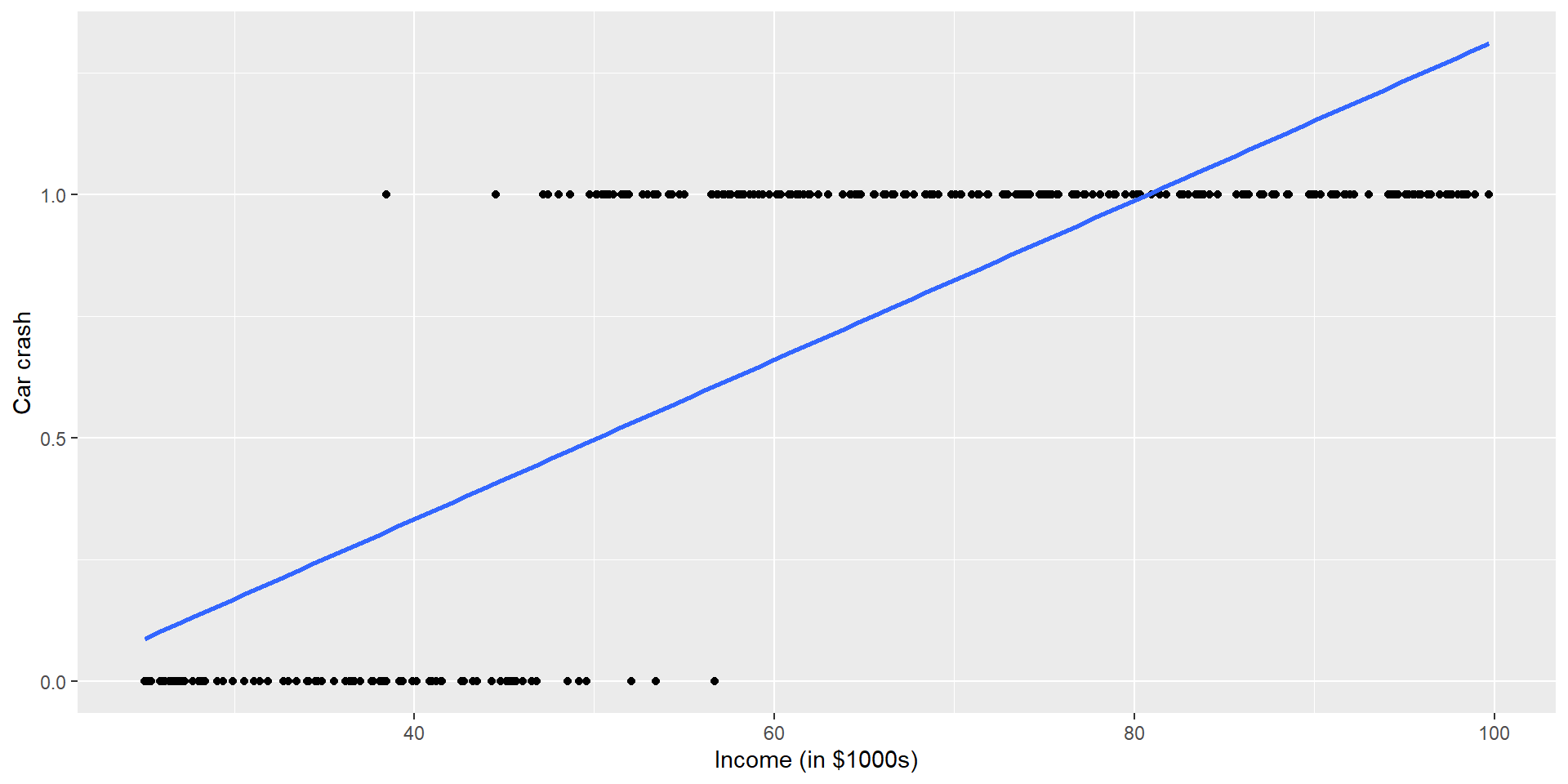
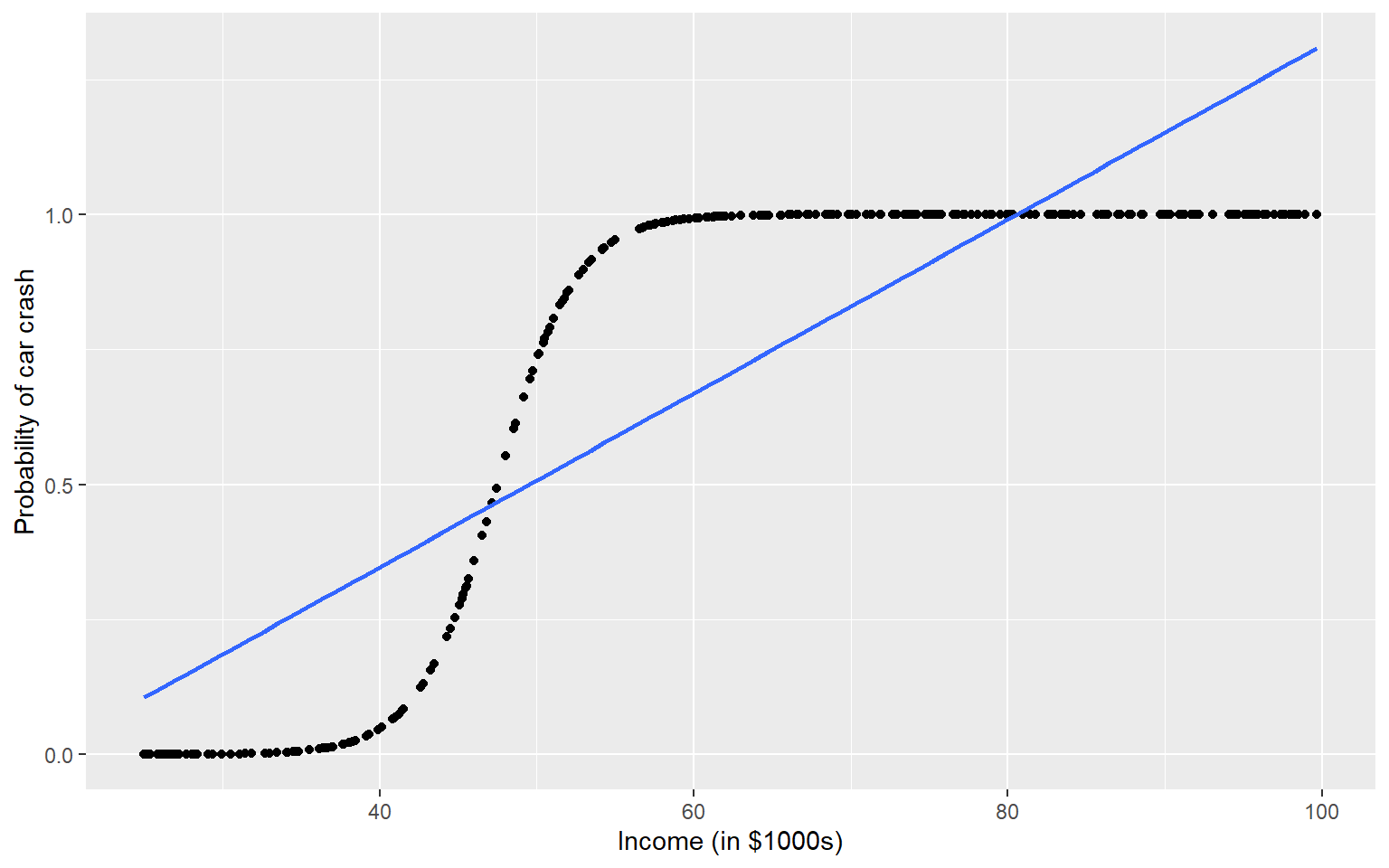
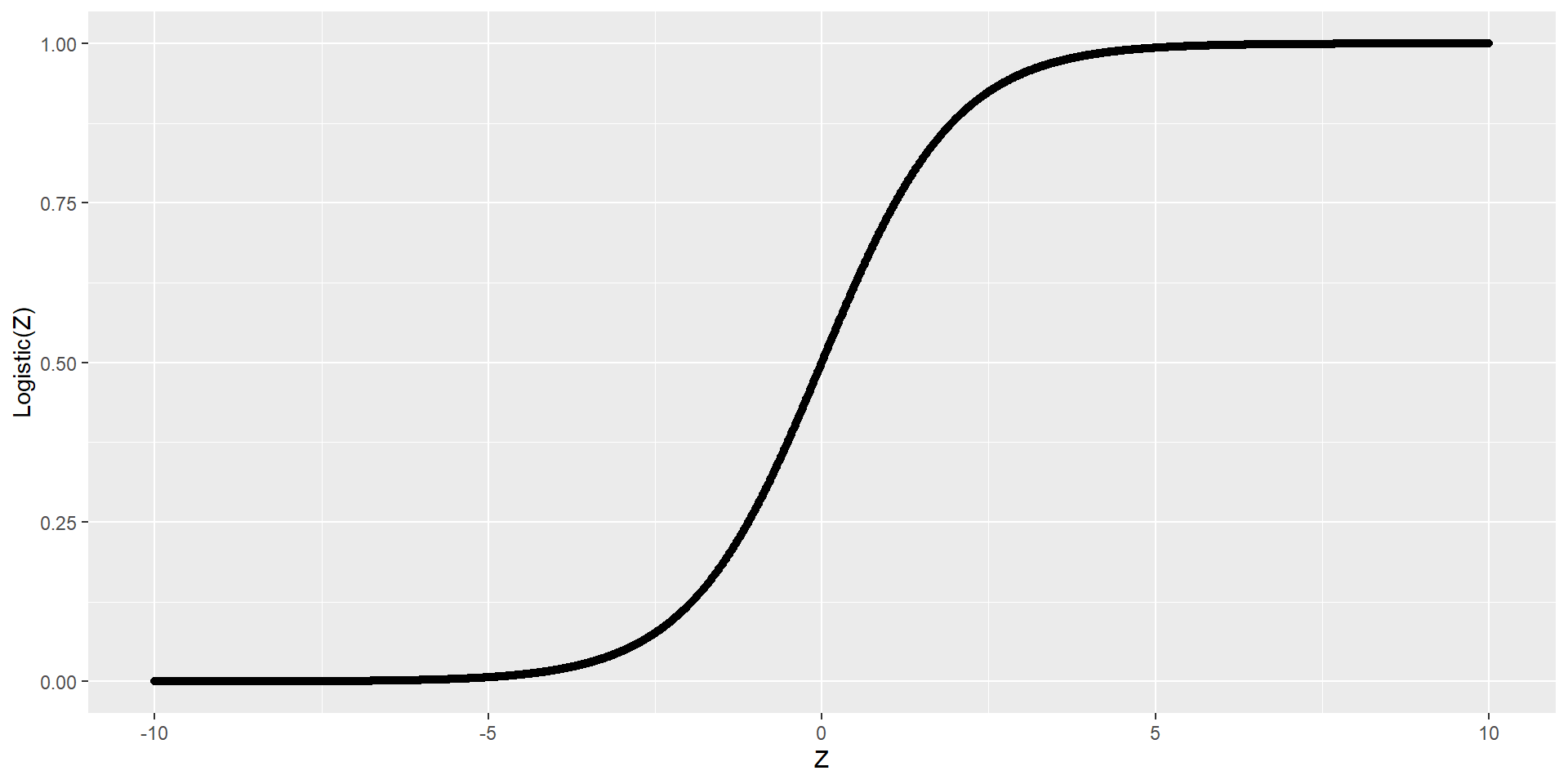
\[\log(\frac{\pi}{1 - \pi}) = \beta_0 + \beta_1 X_1 + ... + \beta_{p-1} X_{p-1}\] Now we have a model that connects \(E[Y|X] = \pi\) to our data, but how do we interpret the parameters, \(\beta_j\)’s?
Recall for linear regression: \(E[Y|X] = \beta_0 + \beta_1 X\)
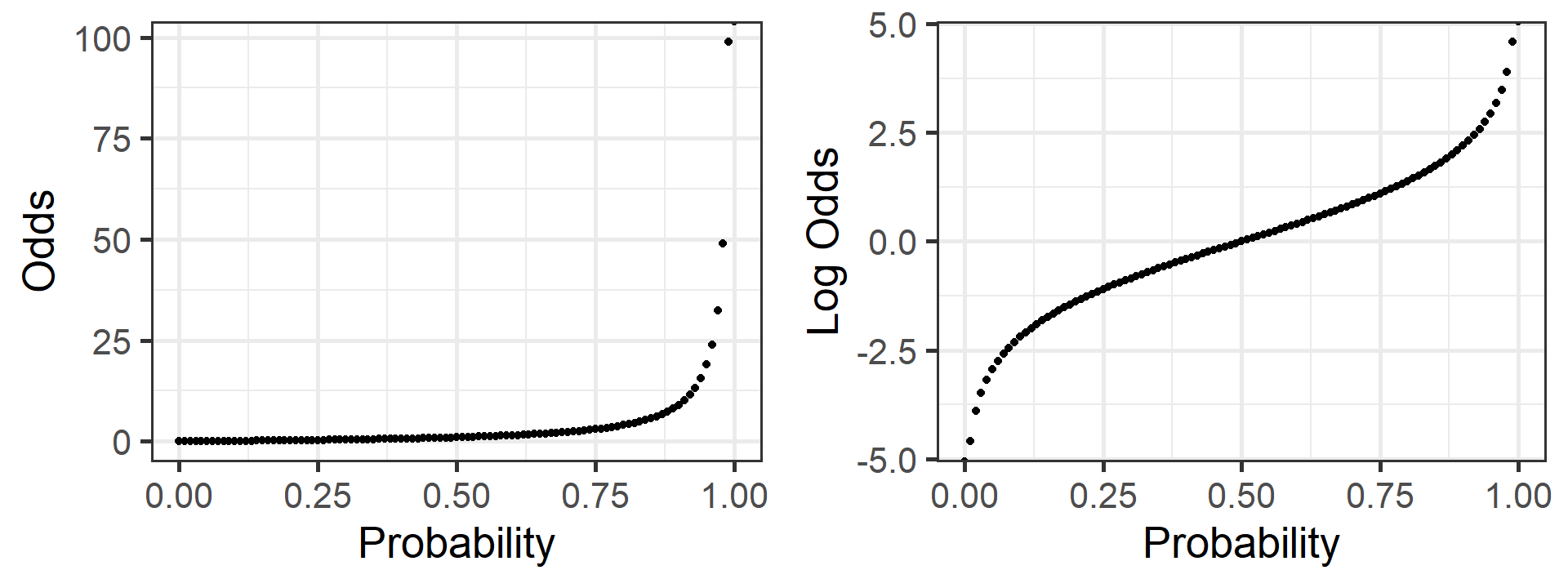
We typically interpret the odds ratio \(e^{\beta_1}\) instead of log odds ratio \(\beta_1\)
If \(e^{\beta_1}\) = 1
If \(e^{\beta_1}\) < 1
If \(e^{\beta_1}\) > 1
Parameter Estimation: MLE
We want the Maximum Likelihood Estimate (MLE) for the \(\beta_j\)’s… why?
The MLE aims to find estimates \(\hat{\theta} = \{\hat{\beta}_0, \hat{\beta}_1, ..., \hat{\beta}_{p-1}\}\) that maximize the likelihood function over the parameter space with a given data set.
The likelihood function \(L(\theta | y)\) measures the goodness of fit of a statistical model to a sample of data for given values of the unknown parameters \(\theta\).
The Maximum Likelihood Estimators have desirable asymptotic (large sample size) properties
Parameter Estimation: MLE for Logistic Regression
We want to find estimators \(\hat{\beta_0}, \hat{\beta_1}, ..., \hat{\beta_p}\) that maximize \(L(\theta | y)\)
For simple linear regression we can directly solve for the maximum likelihood estimators and they happen to be identical to the least square estimators
For logistic regression we can’t directly calculate the estimators, we have to use optimization algorithms. Luckily those are implemented for us!
Inference With Logistic Regression
In linear regression we used a t-test to test for statistically significant features.
Beware in logistic regression there are different tests that can be used (we will talk about these)
Likelihood Ratio Test
Wald Test
Know which one your software is using!
Classification / Prediction With Logisitic Regression
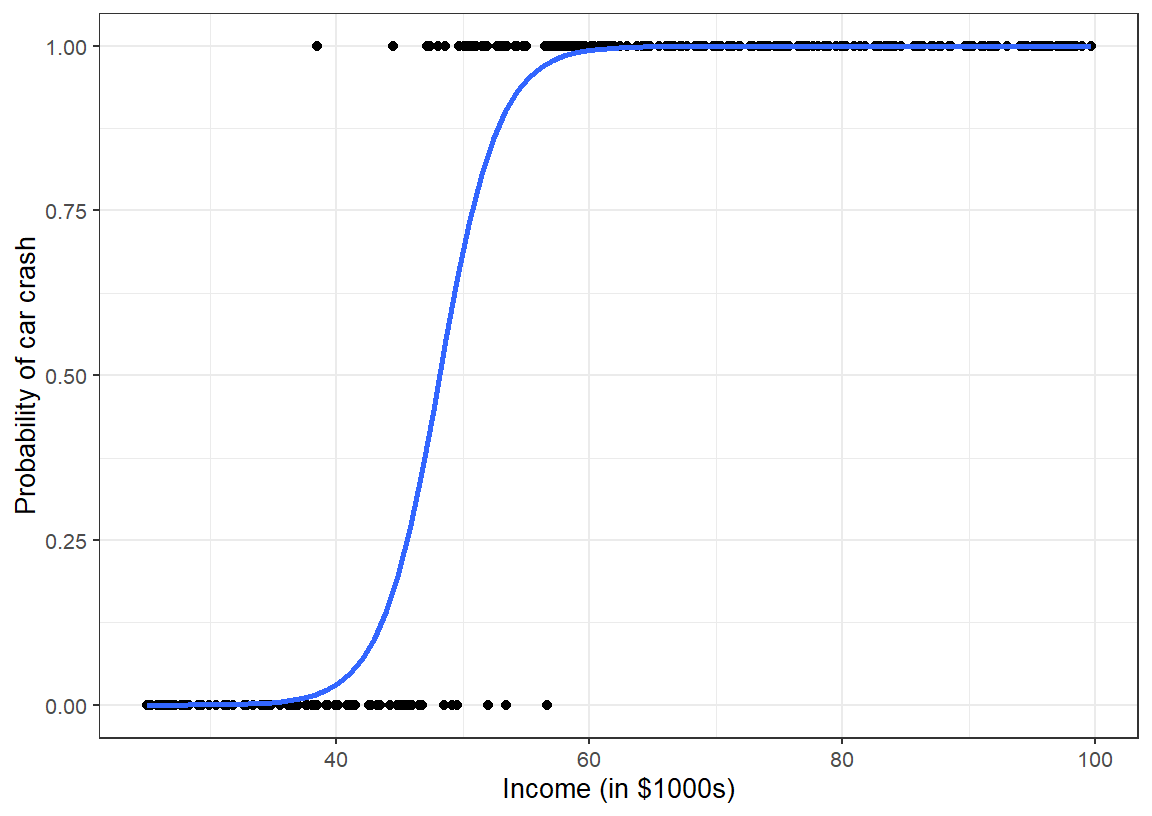
How do we convert the predicted probabilities to values of \(Y\) (e.g., 0 vs 1 or TRUE vs FALSE)?
The cutoff should be a domain knowledge-based decision. The natural cutoff with no context would be 0.5
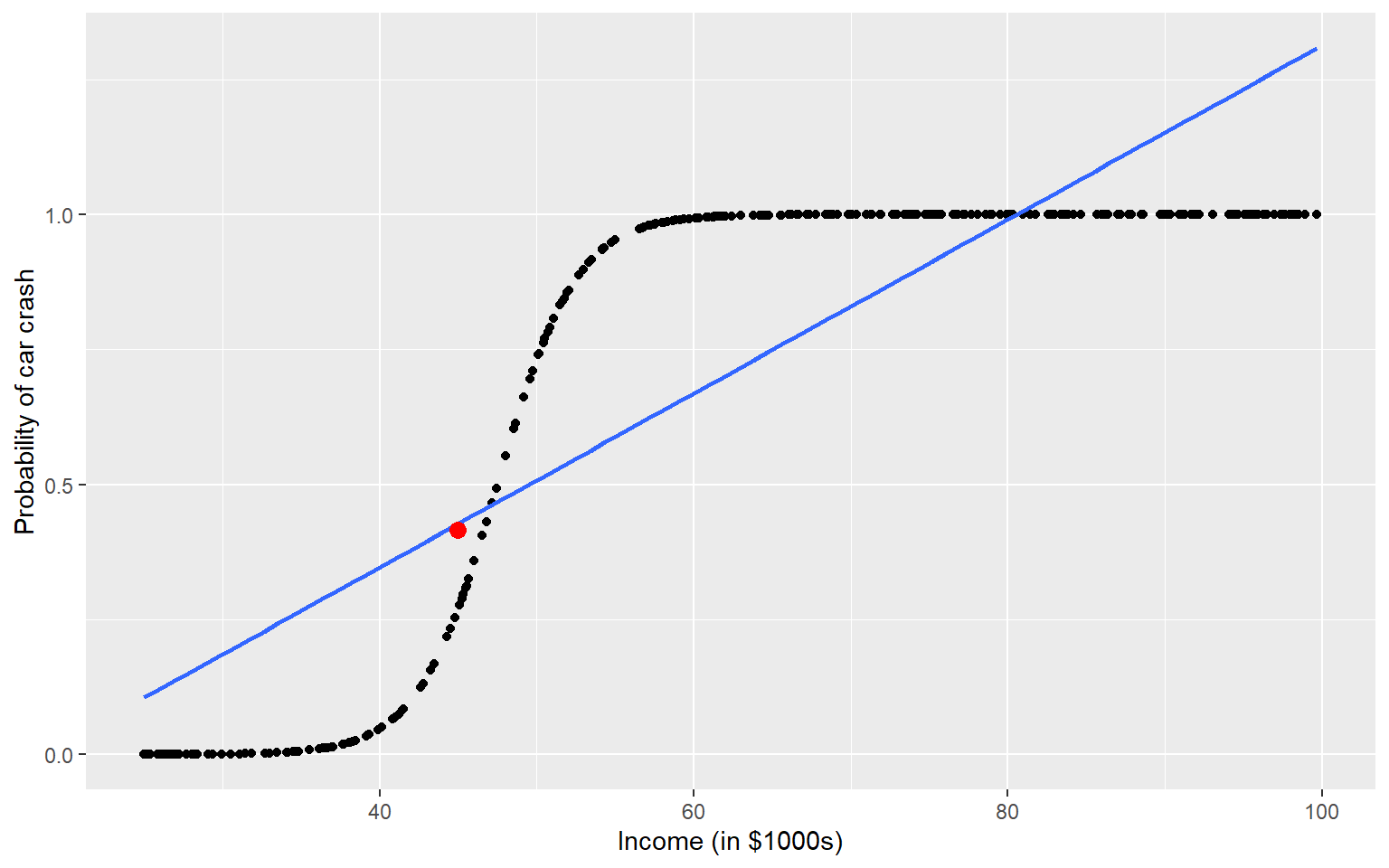
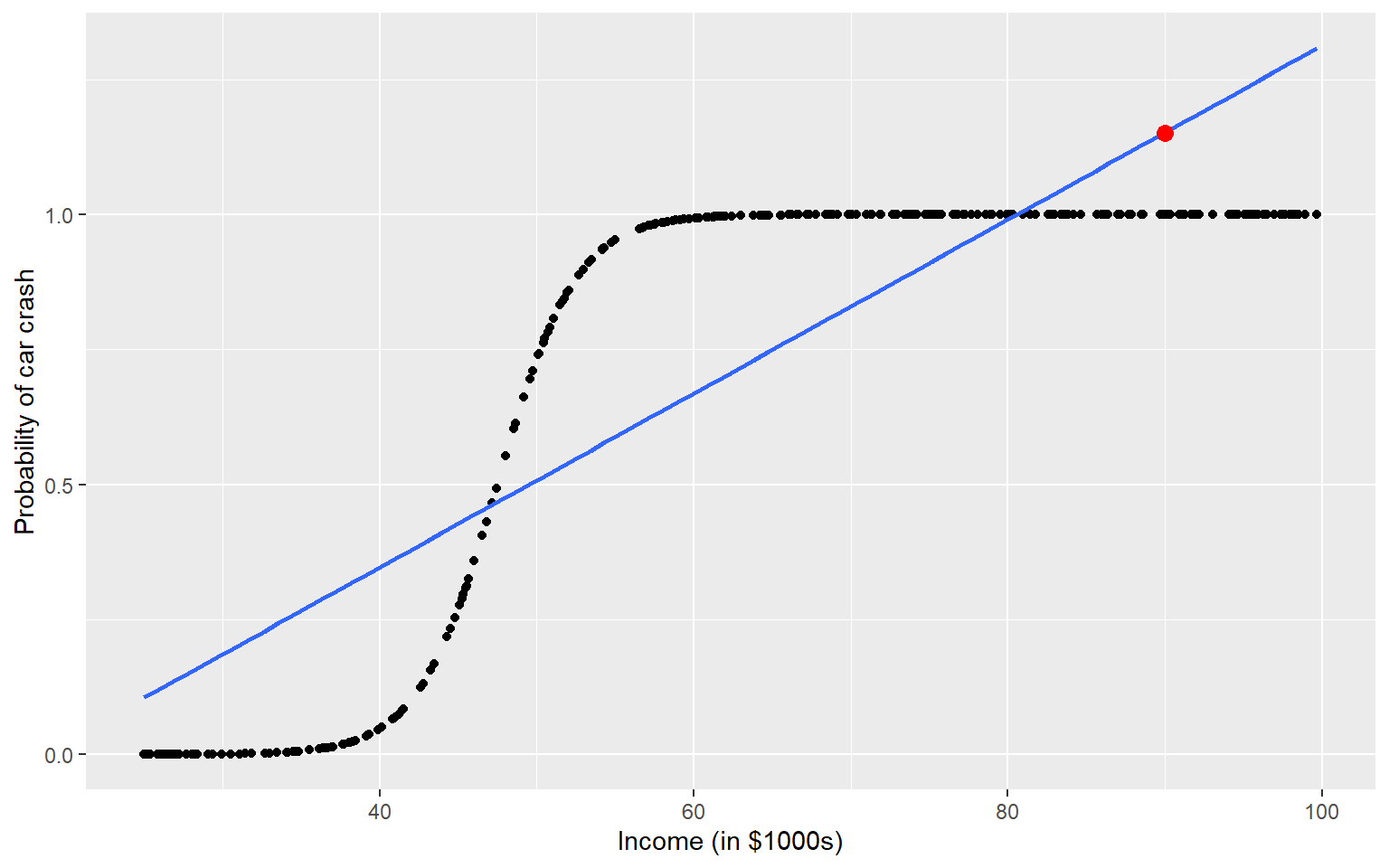
ggplot(sim_crash_data, aes(y = car_crash, x = income)) +geom_point() +geom_smooth(method = glm, se =FALSE, method.args =list(family ="binomial") ) +theme_bw(base_size =10) +labs(y ="Probability of car crash", x ="Income (in $1000s)")
Classification / Prediction With Logisitic Regression
Confusion Matrix
There are many considerations for how “well” our logistic model is predicting